Getting started with preprocessed IXPE data#
Learning Goals#
By the end of this tutorial, you will be able to:
Find and access preprocessed (“level 2”) IXPE data.
Extract events from source and background regions.
Perform an initial spectro-polarimetric fit to the IXPE data.
Introduction#
This notebook is intended to get you started using and analyzing observations taken by the Imaging X-ray Polarimetry Explorer (IXPE); a NASA X-ray telescope that can measure the polarization of incident X-ray photons, in addition to their position, arrival time, and energy.
IXPE’s primary purpose is to study the polarization of emission from a variety of X-ray sources, and it is the first NASA X-ray telescope dedicated to polarization studies. These capabilities mean that IXPE data are, in some respects, unlike those of other X-ray telescopes (Chandra, XMM, eROSITA, etc.), and special care needs to be taken when analyzing them.
Hint
We highly recommend that new users read both the IXPE quick start guide and the recommendations for statistical treatment of IXPE data documentments - links can be found in the ‘additional resources’ section of this notebook.
We do not require the reprocessing of data for this example, the preprocessed (“level 2”) data products are sufficient.
If you need to reprocess the data, IXPE tools are available in the heasoftpy Python package.
Inputs#
The IXPE ObsID, 01004701, of the data we will process (an observation of a blazar, Mrk 501).
Outputs#
Newly generated IXPE spectra-polarimetric data products and supporting files.
Visualizations of count-rate spectra.
Visualizations of polarization spectra.
Runtime#
As of 15th January 2026, this notebook takes ~90s to run to completion on Fornax using the ‘Default Astrophysics’ image and the ‘small’ server with 8GB RAM/ 2 cores.
Imports#
import contextlib
import glob
import itertools
import multiprocessing as mp
import os
import heasoftpy as hsp
import matplotlib.pyplot as plt
import numpy as np
import xspec as xs
from astroquery.heasarc import Heasarc
from matplotlib.ticker import FuncFormatter
Global Setup#
Functions#
Constants#
Configuration#
1. Downloading the IXPE data files for 01004701#
We’ve already decided on the IXPE observation we’re going to use for this example - as such we don’t need an explorative stage where we use the name of our target, and its coordinates, to find an appropriate observation.
What we do need to know is where the data are stored, and to retrieve a link that we can use to download them - we
can achieve this using the IXPE summary table of observations, accessed using astroquery.
The name of the observation table is stored in the HEASARC_TABLE_NAME constant, set up in the collapsed
‘Global Setup: Constants’ subsection above:
HEASARC_TABLE_NAME
'ixmaster'
First, we construct a simple astronomical data query language (ADQL) query to find the row of the observation summary table that corresponds to our chosen ObsID. This retrieves every column of the row whose ObsID matches the one we’re looking for:
query = (
"SELECT * "
"from {c} as cat "
"where cat.obsid='{oi}'".format(oi=OBS_ID, c=HEASARC_TABLE_NAME)
)
query
"SELECT * from ixmaster as cat where cat.obsid='01004701'"
The query is then executed, and the returned value is converted to an Astropy table (necessary for the next step):
obs_line = Heasarc.query_tap(query).to_table()
obs_line
| __row | obsid | name | ra | dec | lii | bii | roll_angle_req | time | end_time | fcw_1 | fcw_2 | fcw_3 | exposure_1 | exposure_2 | exposure_3 | ontime_1 | ontime_2 | ontime_3 | processing_date | public_date | software_version | obs_type | coordinated | issue_flag | status | caldb_version | comments | prnb | title | pi_names | abstract | subject_category | category_code | priority | cycle | __x_ra_dec | __y_ra_dec | __z_ra_dec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| deg | deg | deg | deg | deg | d | d | s | s | s | s | s | s | d | d | ||||||||||||||||||||||||
| object | object | object | float64 | float64 | float64 | float64 | float64 | float64 | float64 | object | object | object | float64 | float64 | float64 | float64 | float64 | float64 | float64 | float64 | object | object | object | int16 | object | object | object | int32 | object | object | object | object | int16 | object | int16 | float64 | float64 | float64 |
| 285 | 01004701 | MRK 501 | 253.4676 | 39.7602 | 63.6001 | 38.8591 | -- | 59769.97458428 | 59772.04337753 | open | open | open | 97794.9257 | 96095.4274 | 97827.2522 | 97916.2185 | 96245.1984 | 97940.3379 | 59780.72141469 | 59788 | Hea_10Mar2022_V6.30_IXPE_21JUNE2022_1.5 | proposed | 0 | archived | -- | IXPE Team | Bla | 7 | 3 | 1 | -0.736947981589561 | -0.218747312767553 | 0.639575863825431 |
From there we can easily identify the ‘data link’ that we need to download the actual data files - we simply pass the query return
to the locate_data method of Heasarc:
data_links = Heasarc.locate_data(obs_line, HEASARC_TABLE_NAME)
data_links
| ID | access_url | sciserver | aws | content_length | error_message |
|---|---|---|---|---|---|
| byte | |||||
| object | object | str31 | str44 | int64 | object |
| ivo://nasa.heasarc/ixmaster?285 | https://heasarc.gsfc.nasa.gov/FTP/ixpe/data/obs/01//01004701/ | /FTP/ixpe/data/obs/01/01004701/ | s3://nasa-heasarc/ixpe/data/obs/01/01004701/ | 1203321946 |
This data link can be passed straight into the download_data method of Heasarc, and our observation data files
will be downloaded into the directory specified by ROOT_DATA_DIR.
Heasarc.download_data(data_links, host="aws", location=ROOT_DATA_DIR)
INFO: Downloading data AWS S3 ... [astroquery.heasarc.core]
INFO: Enabling anonymous cloud data access ... [astroquery.heasarc.core]
INFO: downloading s3://nasa-heasarc/ixpe/data/obs/01/01004701/ [astroquery.heasarc.core]
INFO: Enabling anonymous cloud data access ... [astroquery.heasarc.core]
INFO: downloading s3://nasa-heasarc/ixpe/data/obs/01/01004701/ [astroquery.heasarc.core]
Finally, we’ll take a quick look at the contents and structure of the downloaded data.
It should contain the standard IXPE data files, which include:
event_l1- This directory houses ‘level 1’ event files, which contain raw, unprocessed, event data.event_l2- The ‘level 2’ event files (processed and ready for use) are stored here.auxil- Contains auxiliary data files, such as exposure maps.hk- Contains house-keeping data such as orbit files etc.
Important
There may also be a README file in the root directory of the downloaded data - if this is the case, you should
read it carefully, as it will contain information about any known issues with the processing of the data.
OBS_ID_PATH = os.path.join(ROOT_DATA_DIR, OBS_ID)
glob.glob(f"{OBS_ID_PATH}/*")
['/home/jovyan/project/_data/IXPE/01004701/auxil',
'/home/jovyan/project/_data/IXPE/01004701/event_l1',
'/home/jovyan/project/_data/IXPE/01004701/event_l2',
'/home/jovyan/project/_data/IXPE/01004701/hk']
Hint
For a complete description of data formats of IXPE data directories, see the support documentation on the IXPE Website.
2. Exploring the structure of IXPE data#
The ‘event_l2’ directory contains three event files, one per IXPE detector. We’re going to put the full paths to these files in a directory, with the keys being ‘det1’, ‘det2’, and ‘det3’; this will save us some inelegant string formatting every time we want to access them:
l2_path = os.path.join(ROOT_DATA_DIR, OBS_ID, "event_l2")
l2_path_files = os.listdir(l2_path)
evt_file_paths = {
"det{}".format(f.split("det")[-1][0]): os.path.join(l2_path, f)
for f in l2_path_files
}
evt_file_paths
{'det1': '/home/jovyan/project/_data/IXPE/01004701/event_l2/ixpe01004701_det1_evt2_v01.fits.gz',
'det2': '/home/jovyan/project/_data/IXPE/01004701/event_l2/ixpe01004701_det2_evt2_v01.fits.gz',
'det3': '/home/jovyan/project/_data/IXPE/01004701/event_l2/ixpe01004701_det3_evt2_v01.fits.gz'}
Now, we’ll quickly examine the structure of the event files using a HEASoft tool called fstruct - rather than
going to the command line, we will simply use a HEASoftPy interface:
out = hsp.fstruct(infile=evt_file_paths["det1"], allow_failure=False).stdout
print(out)
No. Type EXTNAME BITPIX Dimensions(columns) PCOUNT GCOUNT
0 PRIMARY 8 0 0 1
1 BINTABLE EVENTS 8 48(10) 101073 0 1
Column Name Format Dims Units TLMIN TLMAX
1 TRG_ID J
2 TIME D s
3 STATUS 16X
4 STATUS2 16X
5 PI J chan 0 374
6 W_MOM E
7 X E pixel 1 600
8 Y E pixel 1 600
9 Q D
10 U D
2 BINTABLE GTI 8 16(2) 95 0 1
Column Name Format Dims Units TLMIN TLMAX
1 START D
2 STOP D
3. Extracting spectro-polarimetric data products#
Here we get to the fun part - the creation and analysis of some IXPE data products!
Defining source and background regions#
To obtain source and background spectra from the ‘level 2’ event lists, we need to define source and background regions for the extraction.
Defining regions can be done in a number of ways, using automated source finding tools, drawing them onto images using SAOImage DS9, or (as we show here) by manually constructing region files.
In this case we define the source region as a \(60^{\prime\prime}\) circle centered on Mrk 501.
The background region is an annulus with an inner radius of \(132^{\prime\prime}\) and outer radius \(252^{\prime\prime}\).
The region files should be independently defined for each telescope; in this example, the source location has the same celestial coordinates within 0.25” for all three detectors, so a single source and a single background region can be used.
with open(os.path.join(OUT_PATH, "src.reg"), "w") as srco:
srco.write('circle(16:53:51.766,+39:45:44.41,60.000")')
with open(os.path.join(OUT_PATH, "bck.reg"), "w") as bcko:
bcko.write('annulus(16:53:51.766,+39:45:44.41,132.000",252.000")')
Running the extractor tool#
Spectro-polarimetric data products will be extracted using another HEASoft tool called extractor. Again, we will
use the HEASoftPy interface rather than running directly in the command line.
Our goal is to extract I, Q, and U spectra (within the source and background regions defined above) from IXPE ‘level 2’ event lists, for every detector. That means there will be three source spectra, and three background spectra, per detector.
Help information for all HEASoftPy tools can be displayed using the help() function:
help(hsp.extractor)
Help on function extractor in module heasoftpy.fcn:
extractor(args=None, **kwargs)
Parameters
----------
exitnow : Exit now: (default: no)
filename (Req) : Input file name: (default: good.evt)
eventsout (Req) : Name of output events file: (default: NONE)
imgfile (Req) : Image output file name: (default: none)
binf : Rebinning factor for region selection: (default: 1)
fullimage : Output image is full-size? (default: yes)
phafile (Req) : PHA output FITS file name: (default: test.pha)
specbin : Binning factor for spectrum: (default: 1)
wtmapb : Build a WMAP for the spectrum? (default: yes)
wtmapfix : Set WMAP pixels outside selected region to -1? (default: yes)
swmapx : Invert X axis when converting WMAP to IMAGE coordinates (default: no)
swmapy : Invert Y axis when converting WMAP to IMAGE coordinates (default: no)
binh : Rebinning factor for WMAP histogram selection: (default: 1)
wmapver : HDUVERS number for the output WMAP format (default: 2)
fitsbinlc (Req) : Name of fits binned light curve: (default: NONE)
qdpfile : QDP light curve output file name: (default: NONE)
binlc (Req) : Bin size for light curve: (default: 64)
lcthresh : Light curve threshold: (default: 1.0)
lcthwarn : Light curve threshold warning: (default: 3.0)
lcstart : Light curve start time (in GTI units): (default: -1.0)
lctzero : Set TIMEZERO keyword to first bin of lightcurve?: (default: yes)
unbinlc : Name of unbinned light curve: (default: NONE)
regionfile (Req) : Region file name: (default: test.reg)
timefile (Req) : Time selection file name: (default: none)
adjustgti : Adjust output GTIs to match frame boundaries?: (default: no)
gtinam : Name of the GTI extension in the time selection file: (default: GTI)
xcolf (Req) : Name of X column for image creation/region selection: (default: DETX)
ycolf (Req) : Name of Y column for image creation/region selection: (default: DETY)
zcolf : Name of column for Z axis of image: (default: NONE)
xint : Digitization for image X-axis (unbinned coordinates): (default: 1.0)
yint : Digitization for image Y-axis (unbinned coordinates): (default: 1.0)
tcol (Req) : Name of TIME column: (default: TIME)
ecol (Req) : Name of ENERGY column: (default: PI)
stokes (Req) : Stokes parameter option NONE/NEFF/SIMPLE/UNWEIGHTED: (default: NONE)
polwcol : Name of polarization weights column: (default: NONE)
ccol : Name of the column used to index multiple GTIs: (default: CCD_ID)
gcol : Name of the GRADE or PATTERN column: (default: NONE)
gstring : String defining filter on GRADE: (default: NONE)
xcolh (Req) : Name of X column for WMAP histogram: (default: DETX)
ycolh (Req) : Name of Y column for WMAP histogram: (default: DETY)
gtitxt : Name of output GTI text file: (default: NONE)
xronwn : Name of output XRONOS window file: (default: NONE)
events : Name of the EVENTS extension: (default: EVENTS)
gti : Name of the GTI extension in the event file: (default: STDGTI)
timeorder : True if time ordered event files: (default: no)
timeref : TJD time 0 in MJD: (default: 40000.0)
tpixrpar : TIMEPIXR value to use if not in events file: (default: -999.0)
usetpixrsel : Use TIMEPIXR correction when selecting events: (default: no)
eventkey : File with list of keywords you don't want copied:"' (default: NONE)
phamax : Keyword for maximum pha channel: (default: PHA_BINS)
xfkey : Name of keyword for size of X for region: (default: NONE)
yfkey : Name of keyword for size of Y for region: (default: NONE)
xhkey : Name of keyword for size of X for WMAP histogram: (default: NONE)
yhkey : Name of keyword for size of Y for WMAP histogram: (default: NONE)
copyall : Copy all extensions? (default: no)
clobber : Overwrite existing files? (default: yes)
maxgti : Maximum number of GTIs: (default: 1000000)
maxccd : Maximum number of chips: (default: 20)
stride : Size of stride when reading input events: (default: 1000)
mode : (default: ql)
--------------------------------------------------
fhelp-generated text
--------------------------------------------------
To maximize efficiency, and take advantage of the multiple cores we have available, we set up a parallel processing
pool using the multiprocessing module. The call to extractor is wrapped in a function that takes the detector
number and the region file to generate the product within as arguments; the function is defined in the
‘Global Setup: Functions’ subsection near the top of the notebook.
Output files are saved in the OUT_PATH directory, which is set up in the ‘Global Setup: Constants’ subsection.
arg_combs = itertools.product(list(evt_file_paths.keys()), ["src.reg", "bck.reg"])
with mp.Pool(NUM_CORES) as p:
result = p.starmap(extract_spec, arg_combs)
Listing the files in the output directory is a good way to check that the extraction was successful, though the
HEASoftPy call will also raise exceptions if the extraction fails (as we passed allow_failure=False).
os.listdir(OUT_PATH)
['src.reg',
'bck.reg',
'ixpe_det1_bck_I.pha',
'ixpe_det1_src_I.pha',
'ixpe_det2_src_I.pha',
'ixpe_det1_bck_Q.pha',
'ixpe_det1_src_Q.pha',
'ixpe_det2_src_Q.pha',
'ixpe_det1_bck_U.pha',
'ixpe_det1_src_U.pha',
'ixpe_det2_src_U.pha',
'ixpe_det2_bck_I.pha',
'ixpe_det3_bck_I.pha',
'ixpe_det3_src_I.pha',
'ixpe_det2_bck_Q.pha',
'ixpe_det3_bck_Q.pha',
'ixpe_det3_src_Q.pha',
'ixpe_det2_bck_U.pha',
'ixpe_det3_bck_U.pha',
'ixpe_det3_src_U.pha']
Obtaining response files#
Performing any meaningful analysis of IXPE spectro-polarimetric data requires response files that describe the sensitivity and characteristics of the instruments. These include the standard ‘Response Matrix File’ (RMF) and ‘Ancillary Response File’ (ARF) files, which map the detector channels to specific energies and describe how the sensitivity of the detector changes with energy respectively; it also includes the non-standard ‘Modulation Response File’ (MRF) files.
Note
The MRF is defined by the product of the energy-dependent modulation factor, \(\mu\)(E) and the ARF. The modulation factor is what map the ‘photo-electron tracks’ measured by IXPE’s detectors to the physical polarization degree.
For a given IXPE detector, the ‘I’ spectrum requires different response files to the ‘Q’ and ‘U’ spectra.
I - The RMF and ARF describe the response.
Q and U - The RMF and MRF describe the response.
We’re going to fetch these files from the HEASARC CalDB, or rather we’ll fetch links to them, as we can use a remote
IXPE CalDB for our spectral analysis later. The HEASoft tool quzcif allows us to search the remote CalDB - we can
find out more about this tool examining the help information:
help(hsp.quzcif)
Help on function quzcif in module heasoftpy.fcn:
quzcif(args=None, **kwargs)
Parameters
----------
mission (Req) : Name of Mission (default: )
instrument (Req) : Name of Instrument (default: )
detector (Req) : Name of Detector (- if not required) (default: -)
filter (Req) : Name of Filter (- if not required) (default: -)
codename (Req) : Calibration Dataset Codename (default: )
date (Req) : Requested Date in yyyy-mm-dd format (default: )
time (Req) : Requested Time in hh:mm:ss format (default: )
expr (Req) : Boolean selection expression for Boundary params(- if not required) (default: -)
maxret : Maximum number of datasets to print to the screen (<0: return all available rows) (default: -1)
retrieve : Download remote file via ftp or http? (default: no)
clobber : Overwrite existing output file? (default: no)
chatter : Chatter flag (default: 0)
quality : 'Quality value of "good" file (default = 0)' (default: 0)
nfound : Number of datasets found which match selection criteria (default: 0)
mode : (default: ql)
--------------------------------------------------
fhelp-generated text
--------------------------------------------------
Note that the output of hsp.quzcif for a particular detector/file-type combination provides links to multiple files.
This is because there are three sets of response files, corresponding to the different weighting schemes, as well as different versions of those files.
For the ‘NEFF’ weighting, use ‘alpha07_
vv’.For the ‘SIMPLE’ weighting, use ‘alpha075simple_
vv’.For the ‘UNWEIGHTED’ version, use ‘20170101_
vv’.
Where vv is the version number of the response files.
Important
We strongly recommend that you use the latest version of the response files!
For our example, we’re going to use vv = 02 for the RMF and vv = 03 for the ARF and MRF.
Setting response versions#
We’ll set up variables to hold the response version numbers:
rmf_ver = "02"
arf_ver = "03"
mrf_ver = "03"
Using quzcif to get the response files#
Now we use the HEASARC tool to actually fetch the response files:
# Getting the on-axis RMFs, ARFs, and MRFs
resps = {det: {"rmf": None, "arf": None, "mrf": None} for det in evt_file_paths.keys()}
for det in evt_file_paths.keys():
det_str = "DU{}".format(det[-1])
rmf_res = hsp.quzcif(
mission="ixpe",
instrument="gpd",
detector=det_str,
filter="-",
date="-",
time="-",
expr="-",
codename="MATRIX",
allow_failure=False,
)
resps[det]["rmf"] = [
x.split()[0] for x in rmf_res.output if "alpha075_{}".format(rmf_ver) in x
][0]
arf_res = hsp.quzcif(
mission="ixpe",
instrument="gpd",
detector=det_str,
filter="-",
date="-",
time="-",
expr="-",
codename="SPECRESP",
allow_failure=False,
)
resps[det]["arf"] = [
x.split()[0] for x in arf_res.output if "alpha075_{}".format(arf_ver) in x
][0]
mrf_res = hsp.quzcif(
mission="ixpe",
instrument="gpd",
detector=det_str,
filter="-",
date="-",
time="-",
expr="-",
codename="MODSPECRESP",
allow_failure=False,
)
resps[det]["mrf"] = [
x.split()[0] for x in mrf_res.output if "alpha075_{}".format(mrf_ver) in x
][0]
4. Loading spectro-polarimetric data into PyXspec and fitting a model#
We now have everything we need to load the extracted spectra into PyXspec and fit a model to them!
Configuring PyXspec#
Here we configure some of PyXspec’s behaviors. We set the verbosity to ‘0’ to suppress printed output, make sure the plot axes are energy (for the x-axis), and normalized counts per second (for the y-axis).
# Severely imits the output of PyXspec, though chatter = 0 will still
# let some messages through.
xs.Xset.chatter = 0
# Other xspec settings
xs.Plot.area = True
xs.Plot.xAxis = "keV"
xs.Plot.background = True
xs.Fit.query = "no"
xs.Fit.nIterations = 500
Reading the spectra into PyXspec#
This snippet uses our previously defined resps dictionary to load the spectra and their requisite response files
into PyXspec. The ‘I’, ‘U’, and ‘Q’ spectra are all loaded in for each detector. The ‘contextlib.chdir’ statement is
used to change the working directory to the directory containing spectral files so that the spectra can be loaded, and
then to ensure that the working directory is reset.
xs.AllData.clear()
# Dictionary to store sort detector responses into - makes it neater to load them in
resps = {det: resps[det] for det in sorted(resps)}
# Changing directory to the directory we've been writing spectra to, we now
# load them into PyXspec.
with contextlib.chdir(OUT_PATH):
x = 0 # Iterator index to keep the spectrum numbering correct
for det, supp_files in resps.items():
du = int(det[-1])
# ----------- Load the I data -----------
xs.AllData("%i:%i ixpe_det%i_src_I.pha" % (du, du + x, du))
xs.AllData(f"{du}:{du+x} ixpe_det{du}_src_I.pha")
s = xs.AllData(du + x)
# Load response and background files
s.response = supp_files["rmf"]
s.response.arf = supp_files["arf"]
s.background = "ixpe_det%i_bck_I.pha" % du
# ---------------------------------------
# ----------- Load the Q data -----------
xs.AllData("%i:%i ixpe_det%i_src_Q.pha" % (du, du + x + 1, du))
s = xs.AllData(du + x + 1)
# #Load response and background files
s.response = supp_files["rmf"]
s.response.arf = supp_files["mrf"]
s.background = "ixpe_det%i_bck_Q.pha" % du
# ---------------------------------------
# ----------- Load the U data -----------
xs.AllData("%i:%i ixpe_det%i_src_U.pha" % (du, du + x + 2, du))
s = xs.AllData(du + x + 2)
# #Load response and background files
s.response = supp_files["rmf"]
s.response.arf = supp_files["mrf"]
s.background = "ixpe_det%i_bck_U.pha" % du
# ---------------------------------------
x += 2
Selecting the energy range to fit#
We decide to ignore all channels that are outside the 2.0-8.0 keV energy range, as this is the nominal ‘usable’ energy range for IXPE.
Danger
Do not pass integers to ignore when trying to ignore an energy range, as that will actually
ignore a range of channels. So don’t be tempted to use xs.AllData.ignore(“0-2, 8-**”) here!
xs.AllData.ignore("0.0-2.0, 8.0-**")
Setting up the spectro-polarimetric model#
We’ll to fit a fairly standard galactic-hydrogen-column-absorbed (tbabs) power-law model to the data (with a multiplicative constant that accounts for the differing responses of the detectors), but we also include a more unusual, polarization-related, model - ‘polconst’.
This will constrain the polarization angle and fraction of the source, by using exploiting the ‘U’ and ‘Q’ spectra we generated and loaded earlier. By using ‘polconst’ we are intrinsically assuming that the polarization angle is constant with energy.
# Set up the model that we want to fit
model = xs.Model("polconst*tbabs(constant*powerlaw)")
# Set initial guesses for parameter values
model.polconst.A = 0.05
model.polconst.psi = -50
model.TBabs.nH = 0.15
model.powerlaw.PhoIndex = 2.7
model.powerlaw.norm = 0.1
The previous step sets up a different version of our model for each detector but also links many of the parameters. This means that we are jointly fitting the data for each instrument, which increases our constraining power over fitting an individual instrument.
Here we read out the separate models and set the constant multiplicative factor for each instrument.
m1 = xs.AllModels(1)
m2 = xs.AllModels(2)
m3 = xs.AllModels(3)
m1.constant.factor = 1.0
m1.constant.factor.frozen = True
m2.constant.factor = 0.8
m3.constant.factor = 0.9
Running the model fit through PyXspec#
xs.Fit.perform()
We can use the show method to examine the final parameter values of the fitted model (we have to temporarily relax the zero verbosity we set earlier on):
xs.Xset.chatter = 5
xs.AllModels.show()
xs.Xset.chatter = 0
5. Visualizing the results#
We will now extract information from PyXspec and plot various aspects of the fitted models and results using the
matplotlib package. This offers more flexibility than the built-in plotting functions in PyXspec.
A ‘traditional’ X-ray spectrum#
We can fetch the count rate, and energy bin centers, from PyXspec:
# This command will construct a logged-data plot of the spectrum
xs.Plot("lda")
yVals = xs.Plot.y()
yErr = xs.Plot.yErr()
xVals = xs.Plot.x()
xErr = xs.Plot.xErr()
mop = xs.Plot.model()
Using that information, we can plot a ‘traditional’ X-ray spectrum:
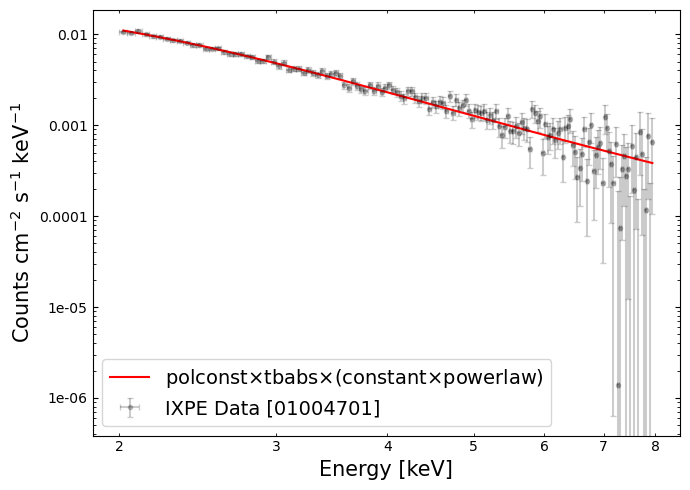
Polarization angle vs. energy#
This part of the data and model is constraining the polarization angle, which by our model choice (particularly the ‘polconst’ component) is assumed to be constant with energy.
We can extract the data and model information that will let us plot the polarization angle against energy:
xs.Plot("polangle")
yVals = xs.Plot.y()
yErr = [abs(y) for y in xs.Plot.yErr()]
xVals = xs.Plot.x()
xErr = xs.Plot.xErr()
mop = xs.Plot.model()
This visualization will help us understand how good the assumption of constant polarization with energy appears to be:
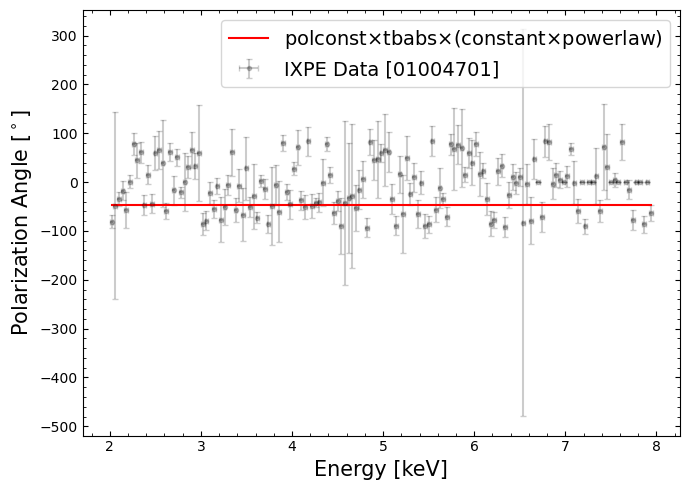
6. Interpreting the results from XSPEC#
There are two parameters of interest in our example; the polarization fraction (A), and the polarization angle (\(\psi\)). The XSPEC error (or uncertainty) command can be used to deduce confidence intervals for these parameters.
We can estimate the 99% confidence interval for these two parameters.
# We're using the XSPEC error command to estimate parameter uncertainties
# Parameter 1 is the polarization fraction
xs.Fit.error("6.635 1")
# Parameter 2 is the polarization angle
xs.Fit.error("6.635 2")
Of particular interest is the 2D error contour for the polarization fraction and polarization angle - we use XSPEC’s
steppar command to ‘walk’ around the polarization fraction and angle parameter spaces.
lch = xs.Xset.logChatter
xs.Xset.logChatter = 20
# Create and open a log file for XSPEC output.
# This step can sometimes take a few minutes. Please be patient!
logFile = xs.Xset.openLog(os.path.join(OUT_PATH, "steppar.txt"))
xs.Fit.steppar("1 0.00 0.21 41 2 -90 0 36")
# Close XSPEC's currently opened log file.
xs.Xset.closeLog()
With the error estimation complete, we’ll extract the plotting information from pyXspec:
# Fetch the plotting information
xs.Plot("contour ,,4 1.386, 4.61 9.21 13.81")
yVals = xs.Plot.y()
xVals = xs.Plot.x()
zVals = xs.Plot.z()
levelvals = xs.Plot.contourLevels()
statval = xs.Fit.statistic
Then plot the error contour for our two polarization parameters.
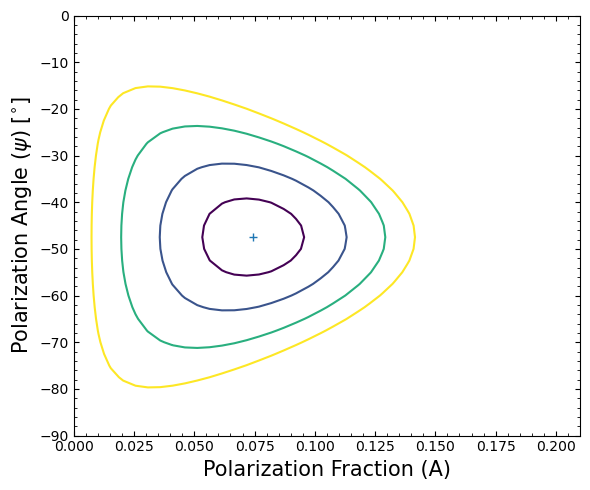
Determining the flux and calculating MDP#
Note that the detection is deemed “highly probable” (confidence C > 99.9%) as A/\(\sigma\) = 4.123 >\(\sqrt{-2 ln(1- C)}\), where \(\sigma\) = 0.01807 as given by XSPEC above.
Finally, we can use PIMMS to estimate the Minimum Detectable Polarization (MDP).
To do this, we first use XSPEC to determine the (model) flux on the 2-8 keV energy range:
xs.AllModels.calcFlux("2.0 8.0")
Extract the calculated fluxes for stokes-I spectra (we know the indices because I-spectra were loaded before Q and U spectra, and each detector was loaded in sequence - note that XSPEC indexing starts at 1, unlike Python):
flux_ispec = []
for sp_ind in [1, 4, 7]:
flux_ispec.append(xs.AllData(sp_ind).flux[0])
flux_ispec
[7.942901256897255e-11, 7.589054935135048e-11, 7.084215422150606e-11]
Now we can easily calculate the mean flux:
np.mean(flux_ispec)
np.float64(7.538723871394304e-11)
We set up a powerlaw model in PIMMS, passing parameters that match the model we just fit and the flux we just calculated:
Galactic hydrogen column density (\(n_{H}\)) \(=0.646\times 10^{22}\:\rm{cm}^{-2}\)
Photon index (\(\Gamma\)) \(= 2.75\)
Average flux from the three detectors (\(f_{\rm{X}}\)) \(=7.54\times 10^{-11}\) erg cm\(^{-2}\) s\(^{-1}\)
When simulating IXPE, we find that PIMMS returns a ‘MDP99’ of 5.62% for a 100 ks exposure.
Scaling by the actual mean of this observation’s exposure time (97.243 ks) gives us an MDP99 of 5.70% meaning that, for an unpolarized source with these physical parameters, an IXPE observation will return a value A > 0.057 only 1% of the time.
This is consistent with the highly probable detection we have found through analysis of this observation - a polarization fraction of 7.45\(\pm\)1.8%.
About this notebook#
Author: Kavitha Arur, IXPE GOF Scientist
Author: David J Turner, HEASARC Staff Scientist
Updated On: 2026-06-01
Additional Resources#
Support: IXPE GOF Helpdesk
Documents: